Who Will Watch The Watchmen? Closing the Loop on Unit Testing With Mutation Testing
Why do we write unit tests? There are a lot of reasons, but I think it generally boils down to one big idea. To prevent regressions.
Consider the following test:
For the following application code:
Our coverage tool tells us this method is 100% covered, but what regressions do this test actually help to prevent?
Not much, really. As long as IEmailSender.SendEmailAsync is invoked with any string, this test will pass. Notice however, that what this method actually seeks to express is that we should call SendEmailAsync with the passed in messageBody converted to all caps.
Yes this test is contrived, and yes it's mock-heavy and yes some may argue that such a test should never be written. That's a fair position, but bear with me.
For this one small, easily digestible method and simple test case, we can eyeball it and probably catch this oversight, but suppose we're in a real production code-base with thousands of tests and possibly hundreds of thousands of lines of application code being worked on by dozens of different developers across multiple years. How can we ever hope to scale up this level of review?
Enter Mutation Testing
You know how sometimes when you're writing unit tests you'll flip the assertion to see if the test is actually doing anything?
Mutation testing is kind of like an automated version of that.
To be more specific, mutation testing works like this:
- A project's unit tests are run to give a baseline of passing tests.
- The project's application code is "mutated" - lines are changed according to various rules such as line removal, string method changing, block removal, arithmetic operation changing, etc.
- The project's unit tests are run again. If the tests still pass with the mutations, those mutations are said to have "survived" which means the tests did not catch those changes. In other words, those regressions were not prevented by the tests.
For this demonstration, I'm going to be using a tool called Stryker. I'm using their Stryker.NET tool because I'm writing C#, but they also have StrykerJS for JavaScript and Stryker4s for Scala. Even though I'm nobody in particular, I'd still like to point out that I have no affiliation with Stryker. I just happen to personally like and use Stryker.NET.
The Stryker docs are easy enough to follow on how to get started so I'm not going to cover that here. Let's skip to the part where we run the tool on our code.
After doing some basic Stryker configuration and running dotnet stryker in the project's root, Stryker spits out an HTML file for us at {project-root}/StrykerOutput/{datetime}/reports/mutation-report.html. Let's open that file in our browser.
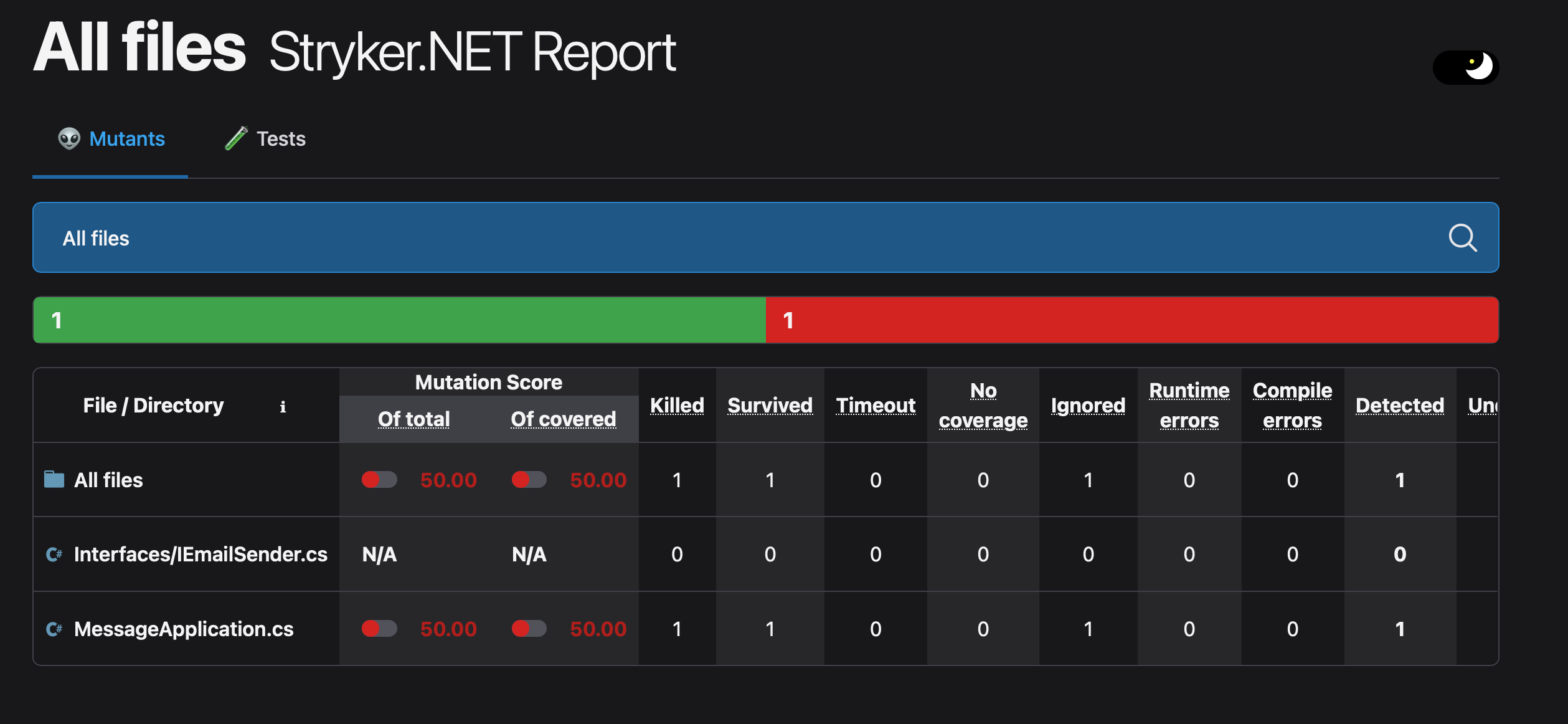
Notice that the "Mutation Score" for MessageApplication.cs - our class from the earlier example - is 50. Let's click into there and see what that means.
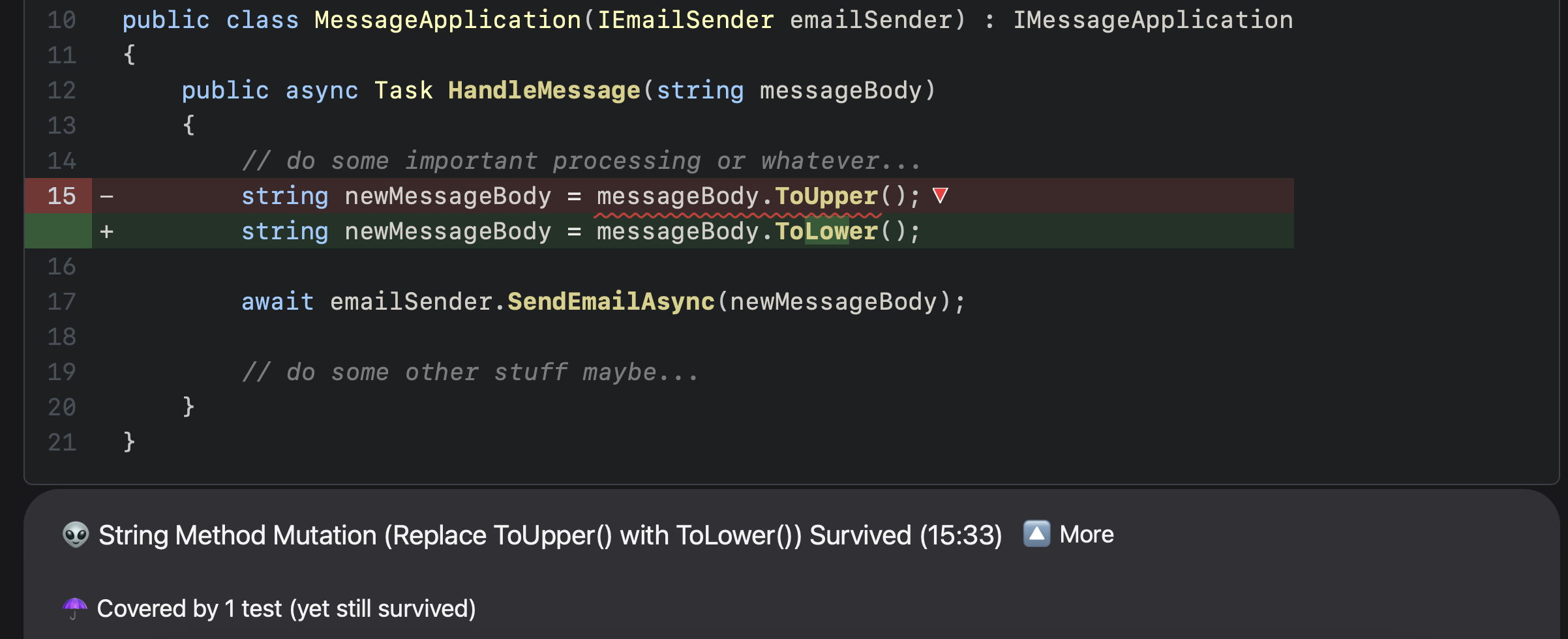
When we drill into this page for the MethodApplication.cs class, we see the following:
- what appears to be a diff showing
messageBody.ToUpper()being changed tomessageBody.ToLower() - "String Method Mutation (Replace ToUpper() with ToLower()) Survived"
- "Covered by 1 test (yet still survived)"
What does this tell us?
Given our example application and test code, if someone were to change messageBody.ToUpper() to messageBody.ToLower(), our tests would not catch that regression. That PR could easily be merged and deployed to production unless the right diligent reviewer happened to notice that specific line being changed and recall the specific business requirement requiring that message to be capitalized, or at the very least, spend extra time going around asking people what's going on here and if it's supposed to be this way.
Let's take what we learned here, and try to write a better test. One that actually encodes the requirements and prevents this regression.
Once again, let's run dotnet stryker and pop over to the Stryker report dashboard.
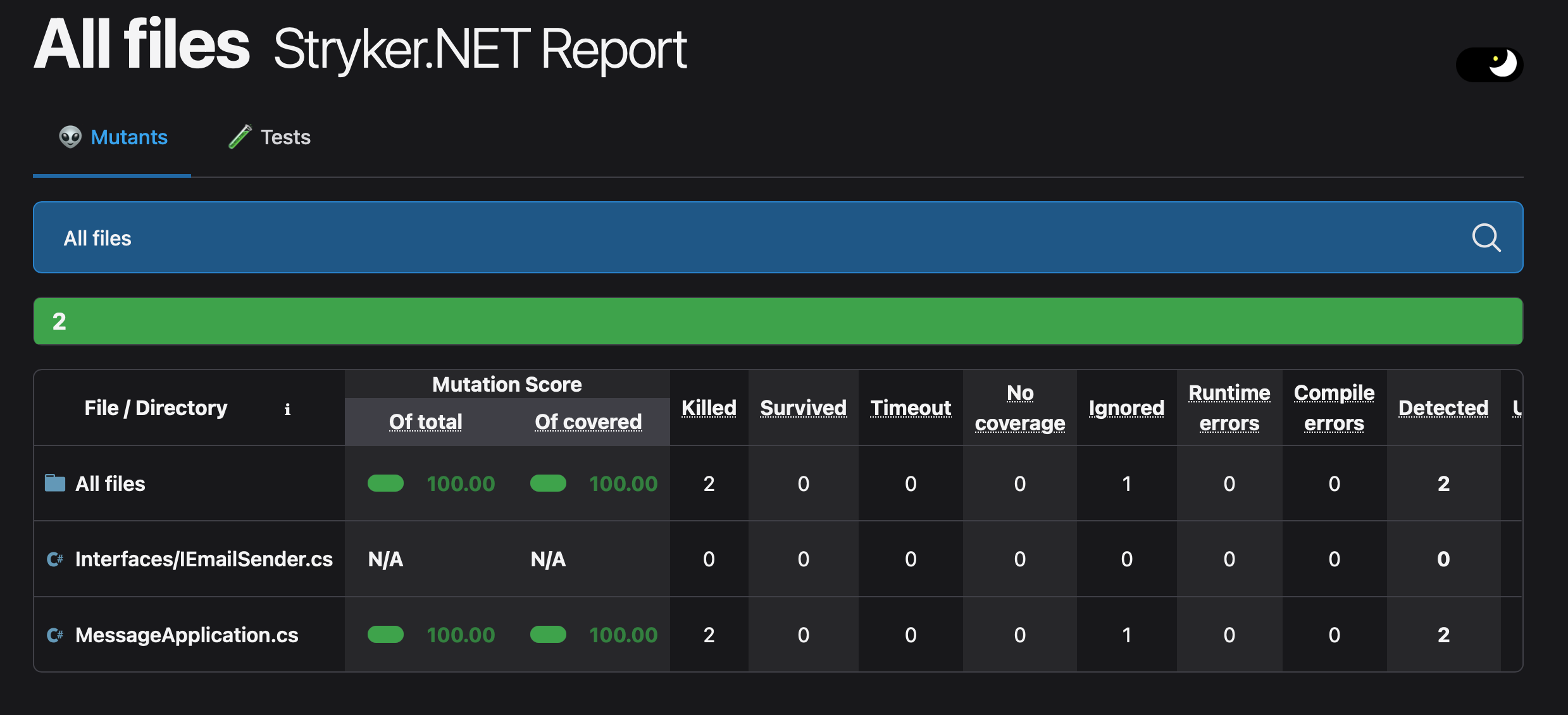
This time we can see we have a mutation score of 100. None of the mutations survived and our unit tests fully encode the behaviour of this method. In order to change the way this method works now, unit tests will also have to be changed. This should not happen on accident and the confidence in our code and our tests should be increased.
Why Not Integration Tests?
Integration tests are expensive!
I'm certainly not saying you shouldn't have integration tests or even that you shouldn't prioritize them over unit tests. However, they are relatively more expensive to develop and maintain than unit tests. In some cases, you may have to deal with complicated auth setups, creating mock users for testing, modify infrastructure, whatever. It can be a lot of work to go from 0 to 1 when it comes to integration tests.
In contrast, mutation testing can be added to your CICD pipeline in an hour. It doesn't even have to (and probably shouldn't) block the pipeline on fail, at least not right away. As you saw earlier, the output of Stryker is an HTML artifact that can sit helpfully alongside a PR to give reviewers additional context.
In Conclusion
Mutation tests can help you close the loop on unit testing by automating the testing of the tests themselves in a way that is low-cost and easy to configure.
The accompanying code for this article along with a full sample project can be found on my GitHub: https://github.com/dmailloux/MutationTesting